Use Transfer Learning to Classify images in CIFAR-100 Dataset
Transfer Learning - Use a pretrained Resnet model trained on ImageNet to classify CIFAR-100 images
In this post we will see how to use transfer learning (where we use the information/patterns that a model has learned in one task to solve another similar task) .
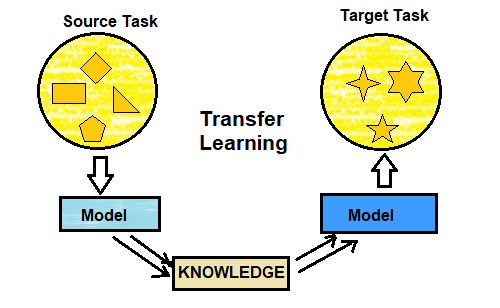
We will use a pretrained ResNet model trained on ImageNet dataset to learn and classify images in the CIFAR-100 dataset.
We will use a ResNet34 pretrained model from https://github.com/qubvel/classification_models
We will use Resnet34 model to try and achieve 80% validation accuracy . Since pretrained weights are only available for imagenet and models expect a 224x224 image size , we will resize the cifar100 images to 224x224 while training .
In the pretrained model we will remove the top prediction layers and freeze the last 11 layers . We will add a GlobalAveragepooling2D layer , a dense layer and a softmax activation to form our prediction layer for cifar100. The first part will be to train with the frozen layers in base model . After training for about 30 epochs , we will unfreeze the layers and train further .
!pip install git+https://github.com/qubvel/classification_models.git
from keras import backend as K
import time
import matplotlib.pyplot as plt
import numpy as np
% matplotlib inline
np.random.seed(2017)
#from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Activation, Flatten, Dropout
from keras.layers import BatchNormalization
from keras.utils import np_utils
import os
import keras
import cv2
#from classification_models.resnet import ResNet34, preprocess_input
from classification_models.keras import Classifiers
ResNet34, preprocess_input = Classifiers.get('resnet34')
from keras.datasets import cifar100
(train_features, train_labels), (test_features, test_labels) = cifar100.load_data()
num_train, img_channels, img_rows, img_cols = train_features.shape
num_test, _, _, _ = test_features.shape
num_classes = len(np.unique(train_labels))
train_features = preprocess_input(train_features)
test_features = preprocess_input(test_features)
print max and min pixel values in the images which we can use in the ramdom-erase/cutout augmentation later
print(np.max(train_features),np.min(train_features))
Store cifar100 train and test images in a local data folder. We will load these images using an imagedatagenerator and resize to 224x224 which is default size for Resnet-imagenet models
!rm -R ./data/ # remove old data direrctory to clean up
sub_dir='train'
data_dir='./data'
if not os.path.exists(data_dir):
os.mkdir(data_dir)
image_dir='./data/'+sub_dir+'/'
if not os.path.exists(image_dir):
os.mkdir(image_dir)
def save_img(images,sub_dir):
c=0
os.chdir('/content/')
curr_dir = os.getcwd()
image_dir='./data/'+sub_dir+'/'
if not os.path.exists(image_dir):
os.mkdir(image_dir)
os.chdir(image_dir)
print('current working directory is '+os.getcwd())
for img in images:
c +=1
filename=str(c)+'.jpg'
cv2.imwrite(filename,img)
print("files resized and saved to "+image_dir)
os.chdir(curr_dir)
print('current working directory is '+os.getcwd())
save_img(train_features,'train')
save_img(test_features,'test')
!ls ./data
from google.colab import drive
drive.mount('/gdrive',force_remount=True)
import pandas as pd
def form_df(label_type='train'):
if label_type=='train':
labels=train_labels
else:
labels=test_labels
file_name=[]
class_label=[]
for i in range(len(labels)):
filename=str(i+1)+'.jpg'
file_name.append(filename)
class_label.append(str(labels[i][0]))
df=pd.DataFrame({'File':file_name,'Class':class_label})
return df
train_df=form_df('train')
print(train_df.head())
train_df.info()
train_df.tail()
test_df=form_df('test')
print(test_df.head())
print(test_df.tail())
print(test_df.info())
def pad4(img):
pad_size=img.shape[1]//8
img=np.pad(img, [ (pad_size, pad_size), (pad_size, pad_size), (0, 0)], mode='reflect')
return img
def random_pad_crop_img(img,crop_size=224):
crop_size=img.shape[1]
img=pad4(img)
pad=img.shape[1]-crop_size
x1=np.random.randint(pad)
x2=x1+crop_size
y1=np.random.randint(pad)
y2=y1+crop_size
img=img[x1:x2,y1:y2,:]
return img
We will now get the ResNet34 model weights for imagenet (Cifar is not available in this library).
input shape set to 224,224,3
Add GlobalAveragePooling to convert these to 1D inputs suitable for the softmax prediction layer
Add a Dense Layer instead of the one we removed from the pretrained model
Add softmax prediction
for the first train run we will freeze the all layers of the pretrained model except the last 11 layers
# build model
from keras.layers import GlobalAveragePooling2D, Add, Lambda, Dense, GlobalMaxPooling2D
#base modek from REsnet34
base_model = ResNet34(input_shape=(224,224,3), weights='imagenet', include_top=False)
#Freeze all but last 11 layers
for layer in base_model.layers[:-11]:
layer.trainable=False
for layer in base_model.layers:
print(layer, layer.trainable)
#Add our own Top/Prediction layers
x = GlobalAveragePooling2D()(base_model.output)
x= Dense(num_classes,use_bias=False)(x)
output = keras.layers.Activation('softmax')(x)
model = keras.models.Model(inputs=[base_model.input], outputs=[output])
from keras.optimizers import SGD
opt=SGD(lr=0.015, momentum=0.9, nesterov=True)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
from keras.callbacks import ModelCheckpoint
model_save_path='/gdrive/My Drive/EVA/session20/best_model2.h5'
chkpoint_model=ModelCheckpoint(model_save_path, monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='max')
Cutout Augmentation
Cutout was first presented as an effective augmentation technique in these two papers :
Improved Regularization of Convolutional Neural Networks with Cutout and Random Erasing Data Augmentation
The idea is to randomly cut away patches of information from images that a model is training on to force it to learn from more parts of the image. This would help the model learn more features about a class instead of depending on some simple assumptions using smaller areas within the image . This helps the model generalize better and make better predictions .
We will use python code for random erasing found at https://github.com/yu4u/cutout-random-erasing
#get code for random erasing from https://github.com/yu4u/cutout-random-erasing
!wget https://raw.githubusercontent.com/yu4u/cutout-random-erasing/master/random_eraser.py
from random_eraser import get_random_eraser
eraser = get_random_eraser(p=0.8, s_l=0.15, s_h=0.25,r_1=0.5, r_2=1/0.5,v_l=0,v_h=255,pixel_level=False)
def img_aug1(img):
img=random_pad_crop_img(img)
img=eraser(img)
return img
def scheduler(epoch):
if epoch < 30:
return 0.01
elif 30 < epoch < 50:
return 0.008
else:
return 0.008 * tensorflow.math.exp(0.1 * (50 - epoch))
lr_callback = keras.callbacks.LearningRateScheduler(scheduler)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
EPOCHS=100
batch_size=128
train_datagen=ImageDataGenerator(
preprocessing_function=img_aug1,
horizontal_flip=True
)
val_datagen= ImageDataGenerator(
)
training_generator = train_datagen.flow_from_dataframe(train_df, directory='./data/train/',
x_col='File', y_col='Class', target_size=(224, 224),
color_mode='rgb', interpolation='bicubic',
class_mode='categorical',
batch_size=batch_size, shuffle=True, seed=42)
validation_generator = val_datagen.flow_from_dataframe(test_df, directory='./data/test/',
x_col='File', y_col='Class',
target_size=(224, 224),interpolation='bicubic',
color_mode='rgb', class_mode='categorical',
batch_size=batch_size, shuffle=True, seed=42)
def scheduler(epoch):
if epoch < 5:
return 0.02
elif 5 < epoch < 12:
return 0.015
elif 12 < epoch < 20:
return 0.010
elif 20 < epoch < 25:
return 0.007
else:
return 0.003
lr_callback = keras.callbacks.LearningRateScheduler(scheduler)
model.fit_generator(training_generator, epochs=30,
steps_per_epoch=np.ceil(train_features.shape[0]/batch_size),
validation_steps=np.ceil(test_features.shape[0]/batch_size),
validation_data=validation_generator,
shuffle=True,
callbacks=[chkpoint_model,lr_callback],
verbose=1)
for layer in model.layers:
layer.trainable=True
opt=SGD(lr=0.01, momentum=0.9, nesterov=True)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
import math
def scheduler1(epoch):
if epoch < 15:
return 0.01
elif 15 < epoch < 30:
return 0.008
else:
return 0.008 * math.exp(0.1 * (30 - epoch))
lr_callback = keras.callbacks.LearningRateScheduler(scheduler1)
model.fit_generator(training_generator, epochs=EPOCHS,
steps_per_epoch=np.ceil(train_features.shape[0]/batch_size),
validation_steps=np.ceil(test_features.shape[0]/batch_size),
validation_data=validation_generator,
shuffle=True,
callbacks=[chkpoint_model,lr_callback],
verbose=1)
def scheduler2(epoch):
if epoch < 15:
return 0.002
elif 15 < epoch < 30:
return 0.001
elif 13 < epoch < 50:
return 0.0005
else:
return 0.0005 * math.exp(0.5 * (50 - epoch))
lr_callback = keras.callbacks.LearningRateScheduler(scheduler2)
opt=SGD(lr=0.002, momentum=0.9, nesterov=True)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
train_datagen=ImageDataGenerator(
#preprocessing_function=img_aug2,
horizontal_flip=True,width_shift_range=0.05, height_shift_range=0.05
)
val_datagen= ImageDataGenerator(
)
training_generator = train_datagen.flow_from_dataframe(train_df, directory='./data/train/',
x_col='File', y_col='Class', target_size=(224, 224),
color_mode='rgb', interpolation='bicubic',
class_mode='categorical',
batch_size=batch_size, shuffle=True, seed=42)
validation_generator = val_datagen.flow_from_dataframe(test_df, directory='./data/test/',
x_col='File', y_col='Class',
target_size=(224, 224),interpolation='bicubic',
color_mode='rgb', class_mode='categorical',
batch_size=batch_size, shuffle=True, seed=42)
model.fit_generator(training_generator, epochs=EPOCHS,
steps_per_epoch=np.ceil(train_features.shape[0]/batch_size),
validation_steps=np.ceil(test_features.shape[0]/batch_size),
validation_data=validation_generator,
shuffle=True,
callbacks=[chkpoint_model,lr_callback],
verbose=1)
Runtime disconnected after 27 epochs . Val accuracy has reached 81.52 . We will stop here although we could load the model again and train for more epochs to see how much farther we could go.
model= keras.models.load_model('/gdrive/My Drive/EVA/session20/best_model2.h5')
Evaluate and print validation loss and validation accuracy
score=model.evaluate_generator(validation_generator)
print('validation loss =',score[0] , ', Validation accuracy =',score[1])